Cats are liquids: Equipercentile equating of different instruments

Equipercentile equating is an alternative version of observed score equating that can accommodate non-normal response distributions. It corrects for differences in mean and standard deviation but also higher distribution moments, such as skewness and kurtosis. This helps harmonize instruments, where, for example, respondents mostly choose high (or low) response options.
“Equipercentile equating” ist eine Variante von “observed score equating”, die auch nicht normalverteilte Antworten harmonisieren kann. Hierbei werden Unterschiede im Mittelwert, der Standardabweichung, aber auch Unterschiede höherer Verteilungsmomente wie Schiefe und Kurtosis bereinigt. Das hilft zum Beispiel beim Harmonisieren von Instrumenten, bei denen Befragte meist hohe (oder niedrige) Antwortoptionen wählen.
DOI: 10.34879/gesisblog.2021.36
Introduction
Last month, we covered a new approach to harmonizing single question instruments for latent constructs in surveys: observed score equating. Specifically, we looked into linear equating, which is a very straightforward implementation of observed score equating. This method has brought us a large step closer to one of the central aims of ex-post harmonization for latent constructs: Respondents who are the same with regard to the measured concept should (on average) be represented with the same numerical value in a harmonized variable, regardless of the source instrument or source survey. Or less abstract: The same number in the harmonized dataset should mean the same, regardless of the data source.
However, while linear equating is already a far cry better than mere linear stretching, it has a limitation: Responses should be approximately normally distributed. Unfortunately, this is often not the case. Response distributions resemble cats: They are fickle and, most importantly, so flexible in shape that they can be considered a liquid.

Response distributions are often skewed, overly broad (platykurtic), or sometimes even bimodal. And in this blog post, we will try to do that variety of shapes justice with another variant of observed score equating: equipercentile equating.
Quick reminder: Observed Score Equating
But first, a quick recap. When harmonizing data on latent constructs measured with different instruments, the core problem is that they translate the real latent construct intensity into different numerical scales. Hence, the same numerical score can mean something completely different depending on the instrument we used. Last month, we introduced observed score equating, which aims to correct these differences in numerical response formats so that respondents who are the same also get the same average number in the dataset 1.
The obstacle is that we only have access to the responses in our datasets and not the true latent construct intensity (e.g., the actual level of political interest) of our respondents. This makes it hard to compare responses to different instruments. Observed score equating solves this problem with the random groups design. If we have data for both instruments randomly sampled from the same population, then we know that the true latent distributions are very similar for both instruments. Differences in response distributions are thus differences caused by the instruments, not true differences in our respondents. If we then align the response distributions, we match respondents based on their position in this shared population.2 That way, respondents with similar construct intensities (i.e., relative position along the ordinally sorted population) are matched with the same number. Last month, we used a very simple approach to align the response distributions. In linear equating, we simply assume responses to be normally distributed which means we only had to align the means and standard deviations.3
Equipercentile equating
If the responses are not normally distributed, however, then linear equating may not be best. To solve such cases, we can instead use equipercentile equating, which matches response distributions via, you guessed it, percentiles.4
The basic idea is as elegant as it is simple. We have data for both instruments from the same population. In that population, we can use the percentiles for each response option as a proxy for respondents’ construct intensity. For example, if you choose a response at the 50th percentile (i.e., the median), it means that one half of the other respondents have a lower intensity, and one half a higher intensity.
With that in mind, we can translate the response options of one instrument into the other by matching responses with the same percentile rank in the shared population: If a “3” in instrument A is at the 25th percentile, it is equivalent to a “4” in instrument B which is also at the 25th percentile for the same population.
Preparing equipercentile equating
The only problem is that survey instruments have a limited number of response options. Consequently, they never represent an exact percentile. Instead, they represent a range of percentiles. If 20% of respondents chose the first response option, this response option bundles respondents from the 0th to the 20th percentile. It also means that we rarely get a perfect percentile match. To solve this problem, we must interpolate percentiles.5 To better understand this process, we will take a closer look in the next segment. Please note, however, that in practice, all of these steps are automatically performed by an equating package, such as equate for R.
Transforming discrete response options into continuous percentiles
Equipercentile equating solves the issue of discrete response options with linear interpolation. Think of the example above: If the first response option is chosen by 20% of respondents, then respondents at the 0th, 1st, 2nd, 3rd, … 20th percentile chose it. Linear interpolation simply assumes that all percentiles in the range are equally likely. Visually, we can draw a straight line from 0 to 20 and then assign the exact middle as the “typical” (average) percentile rank for that response option.
The animation below shows the interpolation process in action. We first transform the response distribution into cumulative frequencies, and then we interpolate this “staircase” of cumulative frequencies into a continuous sequence of lines. This linear interpolation is thus called “continuization” in equating literature.
Converting response options to percentiles
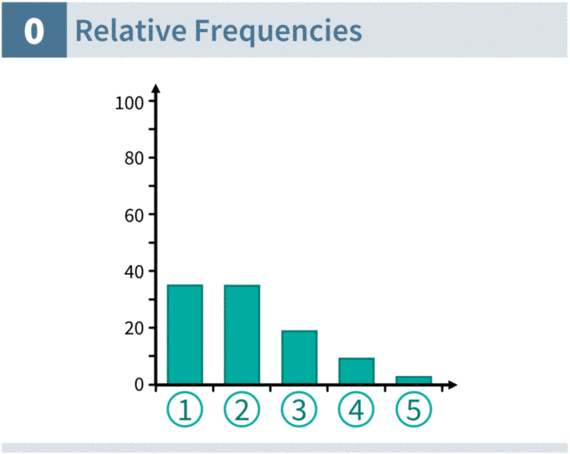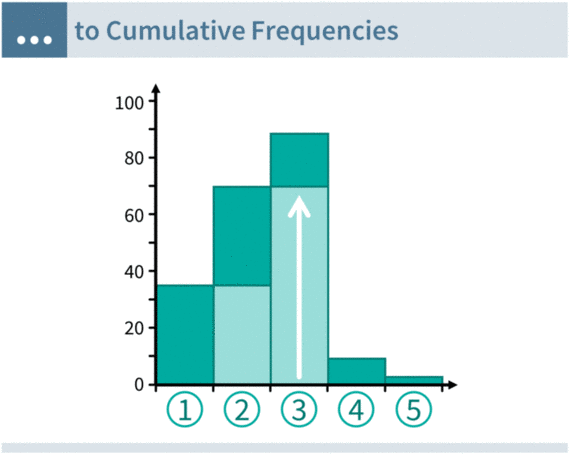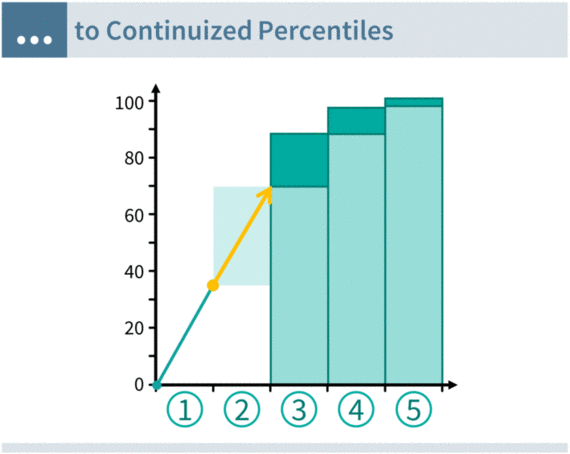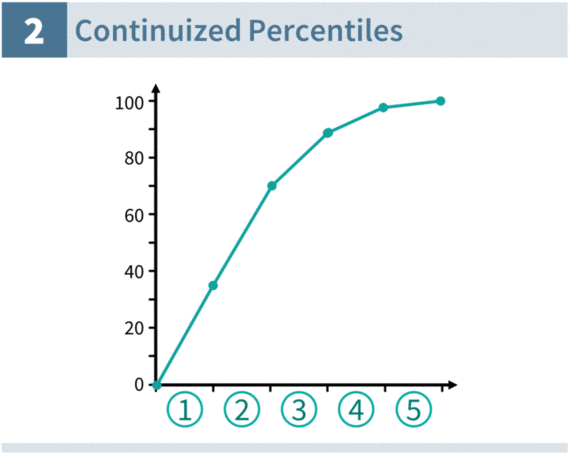
Once that process is done, we can use it in two ways. Firstly, we can transform all response options (i.e., numerical response scores) into percentiles of the population we use for equating:

Converting percentiles back to response options
The second way we can use continuized percentiles is to transform percentiles into response scores. And here, we see the power of linear interpolation. We are not limited to discrete integer response scores (e.g., 1, 2, 3) but can instead get a continuous score for a percentile.

Performing Equipercentile Equating
Once we have understood the idea of continuization, equipercentile equating is trivial. To equate responses to instrument B to the target instrument A, we just need three steps
- Create continuized percentiles for both instruments A and B.
- Transform response options of instrument B into their corresponding percentiles.
- Transform these percentiles into the corresponding response options of instrument A.
In the example below, we have created a continuized percentile curve, one for instrument A and one for B. Based on this, we can translate a “3” in instrument B into its corresponding 46th percentile. And then, we translate this 46th percentile back to a response score of “1.8” in instrument A. The score “3” in B has been equated to a score of “1.8” in A.

The final result
Once we have transformed all responses of instrument B into the format of instrument A, we get, in essence, a recoding table with a transformed value for each response option in instrument B. Then, we can use that table to recode the responses to be with those equivalent values. The result looks like this:

Note how the bars of the equated B instrument are no longer equally far apart. This is different from linear equating and explains why equipercentile equating is more flexible. We also see that equipercentile equating, much like linear equating, aligns the mean and standard deviation. Not pictured here is that equipercentile equating also mitigates differences in higher distribution moments, such as skewness. However, just as a word of caution: We have just aligned the numerical format. Equating does not correct instruments that measure different constructs in the first place, nor does it change the measurement quality of different instruments.6
Conclusion and outlook
I hope to have shown that observed score equating in general and now equipercentile equating, in particular, are helpful tools for harmonization practitioners. For now, we have barely scratched the surface of what are the possibilities of equating. If this has piqued your interest, feel free to get in touch. If you want to try it yourself: The “equate” package for R works for equipercentile equating as well as for linear equating.
However, in our blog series, we will leave equating behind us for now. Instead, next month we will look into alternative harmonization approaches that can be applied during the data analyses process: multiple imputation as well as multi-level modeling with methodological control variables.
References
- Kolen, M. J., & Brennan, R. L. (2014). Test Equating, Scaling, and Linking (3rd ed.). Springer.
- Kolen, M. J., & Brennan, R. L. (2014). Test Equating, Scaling, and Linking (3rd ed.). Springer.
- Kolen, M. J., & Brennan, R. L. (2014). Test Equating, Scaling, and Linking (3rd ed.). Springer.
- Kolen, M. J., & Brennan, R. L. (2014). Test Equating, Scaling, and Linking (3rd ed.). Springer.
- Kolen, M. J., & Brennan, R. L. (2014). Test Equating, Scaling, and Linking (3rd ed.). Springer.
- Kolen, M. J., & Brennan, R. L. (2014). Test Equating, Scaling, and Linking (3rd ed.). Springer.
One comment