Preserving Twitter Data for the Social Science Community

Social media platforms act as the gatekeepers for research data, as they regulate the access to data generated by and used within the platform. Twitter has been probably one of the most research/academia friendly social media-platform which is evident from the high number of publications based on Twitter data. This blog post discusses recent developments in the access to Twitter data, their potential implications, the role of infrastructures institution for enabling data access and a unique research data archive offered by GESIS.
Social-Media-Plattformen fungieren als Gatekeeper für Forschungsdaten, da sie den Zugang zu den von der Plattform erzeugten und verwendeten Daten regeln. Twitter ist wahrscheinlich eine der forschungs- und wissenschaftsfreundlichsten Social-Media-Plattformen, was sich in der großen Anzahl von Veröffentlichungen zeigt, die auf Twitter-Daten basieren. In diesem Blogbeitrag werden die jüngsten Entwicklungen beim Zugang zu Twitter-Daten erörtert, ihre potenziellen Auswirkungen beleuchtet, die Rolle von Infrastrukturen, die den Datenzugang ermöglichen, aufgezeigt und schließlich das einzigartige Forschungsdatenarchiv von GESIS vorgestellt.
DOI: 10.34879/gesisblog.2023.66
The role of archival organizations to preserve evolving Web data
Over the last decade, the availability of large-scale social media data has been instrumental for investigating the dynamic evolution of attitudes and opinions in the context of particular events (such as the COVID-19 pandemic), validating long standing hypotheses in the social sciences (e.g., small world phenomenon) but also for understanding emerging phenomena like filter bubbles and echo chambers. Twitter has emerged as one of the most studied platforms partly due to its generous data access policy. Other platforms such as Facebook followed a different policy and heavily restricted the access to data even for scientific purposes. Overall, social media platforms enable innovative research but also act as gatekeepers to data and negatively impact independent research.
As any other scientific discipline, social science relies on public access to high quality research data. Infrastructural and archival organizations have the responsibility to facilitate such access and mitigate possible risk of third parties restricting and limiting data access. Specifically in the context of dynamically evolving Web data that is constantly being added, deleted or modified, archival is crucial to preserve access over time and to enable an understanding of the history and evolution of discourse and user interactions. While the Internet Archive has been at the forefront of archiving of Web content, more recently, archival organizations dedicated to fostering open science like GESIS have recognized this importance and started providing dedicated Web data offers for the social sciences.
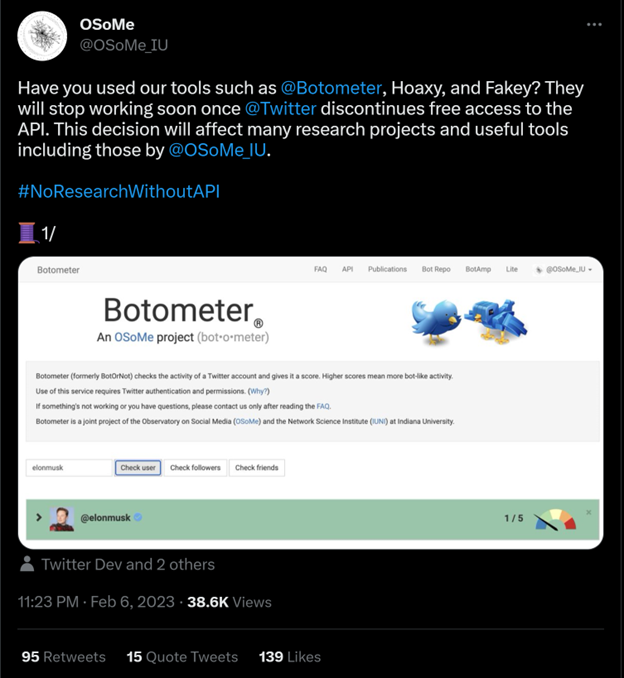
The importance of archival initiatives is even more evident in the light of the recent Twitter developments. While much of academic research had been facilitated by the Twitter APIs, on February 2nd Twitter announced that they will no longer support the free public APIs from February 9 but offer only a paid version instead. Such a change in policy by Twitter puts at risk not only academic and commercial projects but also socially and democracy relevant projects such as Botometer (cf. Fig1) and Politwoops (cf. Fig2). While this date had been postponed frequently, the announcement has led to a strong reaction from the research community and various efforts aimed at gathering available research datasets or harvesting data as long as the APIs provide open access.

Although there are some commendable private initiatives to archive social media and provide access to research data (i.e. Pushishift), reproducibility of research results requires open data archives by public non-profit organizations dedicated exclusively to fostering open science.
Why do we need Twitter Archival?
There is a number of reasons why archival organization like GESIS have an important role to play in preserving access to social web data:
- Long-term independence from commercial third parties, whose interests do not necessarily align with open science principles and who may change access modalities at any point in time.
- Continuous archival of the Twitter data stream ensures that historic data is accessible on any emerging topic and ensures that researchers do not have to rely on post-hoc data collection that can only start after a particular event or topic has been identified, where collection of historic data is strictly constrained by the API restrictions of data providers like Twitter.
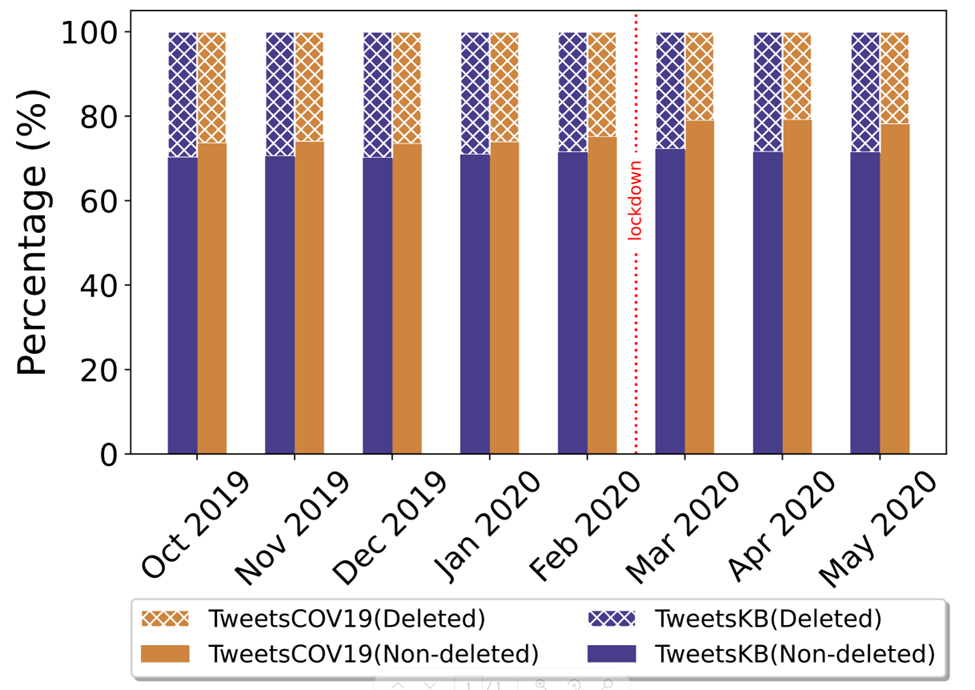
- Persistence of data is a crucial requirement for reproducibility (cf. Fig3). The legal terms of Twitter have led to the current practice of sharing datasets through dehydrated Tweet URIs, i.e., without any actual tweet content, where replication of results requires to rehydrate all tweets at some later point in time. However, that relies on third party access to the actual tweet content (Twitter). While archival organizations like GESIS are not able to share sensitive tweet content widely and publicly, they provide secure means to access and explore archived data in a highly constrained environment. Hence, utilizing data that is persistently archived in such a way also facilitates long-term reproducibility.
- Reproducibility is the key feature supported by relying on public data archives, where the used data is archived for research purposes and transparency about both, used data and the applied methods for retrieval, sampling and interpretation can be ensured.
- Data exploration is crucial for high-quality social media mining results, yet the constraints of third-party APIs do prevent explorative approaches. For instance, while the current academic API of Twitter enables 10 million Tweets per month, 250 Tweets/second, many researchers follow a sequential waterfall-style approach, where (1) information needs are being defined in terms of search keywords (often expert-curated), (2) followed by a data collection step for a certain time period using such keyword and (3) the final data analysis. This approach, however, often suffers from vocabulary mismatches and biases. Using twitter archives data-driven exploration of Twitter discourse can help assess the performance of search terms for retrieval with respect to precision and recall and gradually improve the retrieval method and terms.
GESIS Twitter Archival & TweetsKB
In that context, GESIS has initiated various activities towards preserving access to social media data for the research community. One central activity is the continuous preservation of Twitter data, what – to the best of our knowledge – has led to the largest continuous Twitter archive hosted by non-profit infrastructure organization to facilitate continuous access to Twitter data for research purposes. The archive is created through continuously archiving a 1% sample of Twitter since 2013(cf. Fig 4), and currently contains more than 12 billion tweets as a continuous data archive 1.
In order to overcome legal and ethical challenges in sharing Twitter data, we have created TweetsKB, that is a publicly available research dataset that was created from this crawl. While access to the entire archive is currently confined to the GESIS’ Secure Data Center in order to adhere to legal and ethical standards, TweetsKB itself provides public access to a cleaned and anonymized English-language subset that is enriched with various features to facilitate research.
Specifically, next to basic tweet metadata (mentions, number of favorites, number of retweets etc.) some advanced NLP-based enrichment steps such as named entity recognition and sentiment analysis are applied to identify key entities (e.g., persons or organizations) and emotional sentiments associated with each tweet. Additionally, URLs are extracted and resolved.
The TweetsKB data contains more than 3 billion English tweets and enjoy high popularity with documented more than 27 K data downloads (including 6.000 downloads from unique users).

Applications and use of TweetsKB?
TweetsKB has been used in various research projects in diverse disciplines, e.g., social, political and computer science. Some examples are mentioned below. In SAFE-19, TweetsKB data has been used to study solidarity attitudes on twitter with respect to democracy 2, economy, and health (cf. Fig 5). In a related project called DD4P, data from TweetsKB helped understanding vaccination hesitancy in Germany (cf. FIG 6). AI4Sci is another project based on TweetsKB that addresses the challenge of developing hybrid Artificial Intelligence (AI) methods for detecting and interpreting scientific claims in big data from online discourses 3. The dataset TweetsCOV19 4 is a dataset containing COVID-19-related tweets extracted from TweetsKB that has been used in the COVID-19 Retweet prediction challenge part of the CIKM2020 AnalytiCUP. The task of the challenge was to predict the veracity of a covid-19 tweet, which is an important task with respect to misinformation spreading.


Outlook
With the current uncertainty about the future of public access to Twitter APIs and the prospect of less affordable options in that regard, access to historical data archives has become even more crucial and researchers have started to question their reliance on third-party APIs. While the future of Twitter archival activities like the ones introduced here also relies on some form of data access, we aim to continue preservation of Twitter data in the future and will provide TweetsKB as an openly available research corpus for the community.
References
- Fafalios, P., Iosifidis, V., Ntoutsi, E., & Dietze, S. (2018). Tweetskb: A public and large-scale rdf corpus of annotated tweets. In The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June 3–7, 2018, Proceedings 15 (pp. 177-190). Springer International Publishing.
- Katsanidou, A., Kneuer, M., Bensmann, F., Dimitrov, D., & Dietze, S. (2023). Limitations of democratic rights during the Covid-19 pandemic—exploring the citizens’ perception and discussions on dangers to democracy in Germany. Zeitschrift für Vergleichende Politikwissenschaft, 1-27.
- Hafid, S., Schellhammer, S., Bringay, S., Todorov, K., & Dietze, S. (2022, October). SciTweets-A Dataset and Annotation Framework for Detecting Scientific Online Discourse. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management (pp. 3988-3992).
- Dimitrov, D., Baran, E., Fafalios, P., Yu, R., Zhu, X., Zloch, M., & Dietze, S. (2020, October). Tweetscov19-a knowledge base of semantically annotated tweets about the covid-19 pandemic. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (pp. 2991-2998).
Leave a Reply