#2: Datenqualität in der Sozialwissenschaft: Auf der Suche nach passenden Frameworks zur Beurteilung von Datenqualität

Im ersten Blogbeitrag dieser Reihe haben wir die wachsende Bedeutung von Datenqualität in den Sozialwissenschaften beleuchtet und ein einheitliches Framework für die Bewertung von Datenqualitätsdimensionen vorgestellt. In diesem Beitrag wird erörtert, wie Forschende passende Frameworks zum Testen dieser Datenqualitätsdefinitionen beurteilen und finden können.
In the first blog post of this series, we explored the growing importance of data quality in the social sciences and introduced a unified framework for assessing data quality dimensions. This post discusses how researchers can evaluate and identify suitable frameworks for testing data quality in applied settings.
DOI: 10.34879/gesisblog.2025.94
Hintergrund
Um die Qualität von Daten objektiv zu bewerten, sind häufig kontextspezifische Frameworks erforderlich, welche auf die Besonderheiten bestimmter Datentypen oder Datenqualitätsdimensionen eingehen. So unterscheiden sich beispielsweise die Erhebungsmethoden von Umfragedaten grundlegend von der Sammlung von Social-Media-Daten auf Online-Plattformen. Während Umfragedaten in der Regel auf strukturierten Fragebögen und sorgfältig kontrollierten Stichproben basieren, sind Social-Media-Daten oft unstrukturiert und stammen aus diversen Quellen mit variierender Zuverlässigkeit. Zudem erfordern Social-Media-Daten oft umfangreiche Verfahren zur Datenaufbereitung und -filterung, da sie eine Vielzahl an Informationen umfassen (z. B. Texte, Bilder, Interaktionen wie Likes oder Klicks). Diese Vielfalt macht eine gezielte Auswahl und Bereinigung der Daten für wissenschaftliche Analysen erforderlich. Ein weiterer wichtiger Punkt, der oft im Umgang mit personenbezogenen Daten bedacht werden muss, ist der Datenschutz. Während bei Umfragedaten die Anonymisierung von Befragten in der Regel relativ einfach ist – beispielsweise, indem eine ID verwendet wird, die keine Rückschlüsse auf die Person zulässt – stellt sich die Situation bei Social-Media-Daten deutlich komplexer dar. Social-Media-Daten enthalten oft eine Vielzahl von Informationen, die indirekt auf eine Person zurückgeführt werden können, wie Standortdaten, Zeitstempel oder sprachliche Ausdrucksweisen. Diese zusätzlichen Datenquellen machen die Anonymisierung zu einer größeren Herausforderung, da selbst entfernte direkte Identifikatoren durch Kombination anderer Merkmale wieder rekonstruierbar sein können. Daher erfordert die Anonymisierung von Social-Media-Daten deutlich mehr Aufwand und sorgfältige Methoden, um sicherzustellen, dass die Privatsphäre der betroffenen Personen gewahrt bleibt.
Um diesen Unterschieden gerecht zu werden, müssen Forschende oftmals auf spezifische Frameworks zurückgreifen, um den verschiedenen Anforderungen an die Datenqualität gerecht zu werden. Solche Frameworks bieten eine strukturierte Herangehensweise, die Forschenden bei der Auswahl und Anpassung ihrer Datenquellen unterstützt. Anbei stellen wir die populärsten Frameworks für die beiden zentralen Anforderungen an Datenqualität vor: intrinsisch (Daten sind korrekt) und extrinsisch (Daten sind verwendbar).
Intrinsische Anforderungen
Um intrinsische Anforderungen an die Datenqualität testen zu können, werden in den Sozialwissenschaften in erster Linie sogenannte Error Frameworks herangezogen. Diese konzeptionellen Modelle, wie beispielsweise das Total Survey Error (TSE) Framework von (Groves et al., 2011)1, dienen dazu, verschiedene Fehlerquellen zu identifizieren und zu bewerten. Sie ermöglichen eine differenzierte Betrachtung des gesamten Prozesses der Datenerhebung und helfen dabei, potenzielle Verzerrungen oder “Fehler” zu erkennen, die während der Datensammlung und -analyse auftreten können.
Abbildung 2 veranschaulicht diesen Prozess und zeigt die zentrale Unterteilung der Fehlerquellen in Messung und Repräsentation. Messfehler beziehen sich häufig auf die Validität der erhobenen Daten, welche durch Probleme wie unzureichende Operationalisierung oder Verzerrungen während der Datenerfassung beeinträchtigt werden können. Auf der anderen Seite betreffen Repräsentationsfehler die Generalisierbarkeit der Daten, etwa durch eine unvollständige Abdeckung der Zielpopulation oder Verzerrungen aufgrund von Nonresponse oder unvollständiger Datensätze.
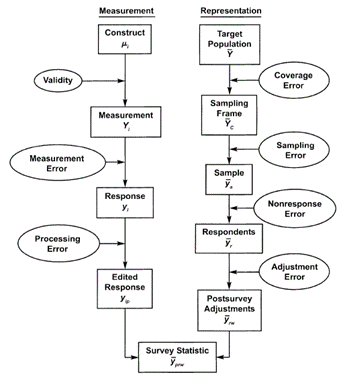
Trotz der allgemeinen Anwendbarkeit solcher Frameworks erfordert die konkrete Bewertung von Fehlern immer eine an die jeweilige Forschungsfrage und das Design des Projekts angepasste Betrachtung. Die intrinsischen Anforderungen an die Datenqualität hängen somit eng mit den Zielen der Studie, den eingesetzten Messmethoden und den spezifischen Kontextbedingungen zusammen, in denen die Daten erhoben und analysiert werden.
Extrinsische Anforderungen
Um extrinsische Anforderungen an die Datenqualität zu erfüllen, können Data Quality Dimension Frameworks als zentrale Werkzeuge herangezogen werden. Diese Frameworks bieten eine strukturierte Herangehensweise, um die wichtigsten extrinsischen Dimensionen Datenqualität systematisch zu bewerten. Dabei spielen insbesondere die FAIR-Kriterien (Wilkinson et al., 2016)2 eine herausragende Rolle, da sie international als Standard für die Sicherstellung von Auffindbarkeit (Findability), Zugänglichkeit (Accessibility), Interoperabilität (Interoperability) und Wiederverwendbarkeit (Reusability) von Daten anerkannt sind. Diese Prinzipien stellen eine solide Grundlage dar, um Daten so zu gestalten, dass sie nutzbar und zugänglich sind. Datenqualitätsframeworks wie das FAIR-Framework werden häufig als Referenz genutzt, da sie sowohl allgemeine Standards als auch spezifische Kriterien für die Bewertung und Optimierung der Datenqualität bereitstellen.
Darüber hinaus existieren jedoch zahlreiche weitere Data Quality Dimension Frameworks, welche nicht nur die FAIR-Prinzipien abdecken, sondern auch zusätzliche extrinsische oder intrinsische Aspekte wie Relevanz, Kohärenz oder Aktualität berücksichtigen. Beispielsweise umfasst das Quality Assurance Framework des European Statistical System3 spezifische Dimensionen, die für konkrete Anwendungsfälle bewertet werden können, um die Datenqualität zu optimieren. Aber auch andere, stärker kontext-spezifische Datenqualitätsframeworks können je nach Anwendungsfall herangezogen werden, um spezifische Anforderungen und Ziele in unterschiedlichen Forschungs- oder Praxisfeldern zu adressieren.
Eine Entscheidungshilfe bei der Suche nach dem passenden Datenqualitätsframework
Die systematische Übersichtsarbeit von Daikeler et al. (2024)4 bietet Forschenden einen umfassenden Überblick über Datenqualitätsframeworks in Form eines Entscheidungsbaums (Decision Tree). Der Entscheidungsbaum kann Forschenden dabei helfen, für verschiedene Kontexte – einschließlich des Datentyps, der Anforderungen (intrinsisch vs. extrinsisch) und der Granularität (Detailebene) – das passende Datenqualitätsframework auszuwählen. Da sich die Anforderungen an die Datenqualität je nach Anwendungsfall erheblich unterscheiden können, stellt ein Entscheidungsbaum eine systematische und effiziente Methode dar, um die Vielzahl existierender Frameworks zu navigieren und gezielt auf die spezifischen Bedürfnisse des Projekts einzugehen.

Der Entscheidungsbaum hilft, nicht nur die passenden Dimensionen und Frameworks auszuwählen, sondern auch Lücken zu identifizieren, in denen bestehende Frameworks bestimmte Aspekte nicht abdecken. Für komplexe Forschungsfragen, welche verschiedene Datentypen und Fehlerquellen kombinieren, kann der Baum zudem dabei unterstützen, mehrere Frameworks zu integrieren oder anzupassen. So können Forschende sicherstellen, dass sowohl spezifische Anforderungen eines Projekts als auch der Kontext, in dem die Daten verwendet werden, berücksichtigt werden.
Ausblick
Sobald geeignete Frameworks zur Orientierung bei der Überprüfung der Datenqualitätsanforderungen ausgewählt sind, kann die praktische Umsetzung zur Sicherstellung der Datenqualität beginnen. Dazu gehören eine sorgfältige Dokumentation sowie die Entwicklung von Strategien zur Minimierung von Fehlern und Verzerrungen. Doch wie lässt sich ein solcher Prozess in der Praxis umsetzen? Der folgende Blogbeitrag gibt anhand konkreter Beispiele einen anschaulichen Einblick in effektive Vorgehensweisen und Strategien.
References
- Groves, R. M., Fowler Jr, F. J., Couper, M. P., Lepkowski, J. M., Singer, E., & Tourangeau, R. (2011). Survey methodology. John Wiley & Sons.
- Wilkinson, M. D., Dumontier, M., Aalbersberg, Ij. J., Appleton, G., Axton, M., Baak, A., Blomberg, N., Boiten, J.-W., da Silva Santos, L. B., Bourne, P. E., Bouwman, J., Brookes, A. J., Clark, T., Crosas, M., Dillo, I., Dumon, O., Edmunds, S., Evelo, C. T., Finkers, R., … Mons, B. (2016). The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data, 3(1), Article 1. https://doi.org/10.1038/sdata.2016.18
- https://ec.europa.eu/eurostat/web/products-manuals-and-guidelines/-/ks-gq-19-006
- Daikeler, J., Fröhling, L., Sen, I., Birkenmaier, L., Gummer, T., Schwalbach, J., Silber, H., Weiß, B., Weller, K., & Lechner, C. (2024). Assessing Data Quality in the Age of Digital Social Research: A Systematic Review. Social Science Computer Review, 08944393241245395. https://doi.org/10.1177/08944393241245395
Leave a Reply